
LLM 最佳部署配置基准测试
简介
有效的 GPU 利用对于部署大语言模型至关重要。Gonka 节点利用定制的 vLLM 推理引擎,支持高性能推理及其验证。
为了获得最佳结果,vLLM 需要仔细的、特定于服务器的配置。最佳性能取决于 GPU 特性和跨 GPU 数据传输速度。本指南提供如何使用 Qwen/QwQ-32 模型作为示例选择 vLLM 参数的说明。我们还将描述哪些参数可以调整以获得最佳性能而不影响验证,以及哪些参数必须保持不变。
理解 vLLM 参数
要配置基于 vLLM 的模型部署,你需要为每个模型定义 args:
"Qwen/Qwen2.5-7B-Instruct": {
"args": [
"--tensor-parallel-size",
"4",
"--pipeline-parallel-size",
"2"
]
}
单个 vLLM 实例使用的 GPU 数量取决于两个参数:
--tensor-parallel-size (TP)--pipeline-parallel-size (PP)
使用的 GPU 数量在大多数情况下等于 TP*PP。
如果 MLNode 拥有的 GPU 数量超过单个实例请求的数量,它将启动多个实例,有效利用可用的 GPU。
例如,如果节点有 10 个 GPU,每个实例配置为使用 4 个,MLNode 将启动两个实例(4 + 4 GPU)并在它们之间进行负载均衡。在许多情况下,部署更多数量的 vLLM 实例,每个实例使用较少的 GPU,可能是更有效的策略。
vLLM 中有两种类型的参数。
| 类型 | 描述 | 参数 |
|---|---|---|
| 影响推理 | 改变输出质量或行为。除非明确允许,否则你不得修改这些参数,因为这可能导致验证失败。 | --kv-cache-dtype--max-model-len--speculative-model--dtype--quantization |
| 不影响推理 | 改变模型如何利用可用的 GPU。 | --tensor-parallel-size--pipeline-parallel-size--enable-expert-parallel |
性能测试
要测量模型部署的性能,你将使用 compressa-perf 工具。你可以在 GitHub 上找到该工具。
1. 安装基准测试工具
首先,使用 pip 安装 compressa-perf:
pip install git+https://github.com/product-science/compressa-perf.git
2. 获取配置文件
基准测试工具使用 YAML 配置文件来定义测试参数。默认配置文件可在此处获得。
3. 运行性能测试
一旦你的模型部署完成,你就可以测试其性能。使用以下命令,将 <IP> 和 <INFERENCE_PORT> 替换为你的具体部署详情,将 MODEL_NAME 替换为你正在测试的模型名称(例如,Qwen/QwQ-32B):
compressa-perf \
measure-from-yaml \
--no-sign \
--node_url http://<IP>:<INFERENCE_PORT> \
config.yml \
--model_name MODEL_NAME
compressa-perf-db.sqlite 的文件中
4. 查看结果
要显示基准测试结果,包括关键指标和参数,请运行:
compressa-perf list --show-metrics --show-parameters
| 指标 | 描述 | 期望值 |
|---|---|---|
| TTFT(首令牌时间) | 生成第一个令牌所经过的时间。 | 越低越好 |
| 延迟 | 模型生成完整响应所花费的总时间。 | 越低越好 |
| TPOT(每输出令牌时间) | 生成第一个之后每个令牌的平均时间。 | 越低越好 |
| 输入令牌吞吐量 | 输入令牌处理速度:总提示令牌 / 总响应时间(每秒令牌数)。 | 越高越好 |
| 输出令牌吞吐量 | 输出令牌生成速度:总生成令牌 / 总响应时间(每秒令牌数)。 | 越高越好 |
部署和性能优化计划
测试在已根据说明部署 MLNode 的服务器上执行。
确保在继续之前已安装性能工具(compressa-perf)并下载了必要的配置文件。
1. 使用强制参数建立初始配置
- 识别网络指定的所有强制参数(例如,
--kv-cache-dtype fp8、--quantization fp8) - 定义基础配置:
"MODEL_NAME": {
"args": [
"--kv-cache-dtype", "fp8",
"--quantization", "fp8",
...
]
}
2. 定义用于测试的潜在部署配置
确定你将实验的可调参数范围。对于不影响推理输出的性能优化,这些主要包括 --tensor-parallel-size (TP) 和 --pipeline-parallel-size (PP) 等参数,以及其他不改变推理结果的参数。
根据服务器的 GPU 和模型大小选择这些参数。单个 vLLM 实例使用的 GPU 数量通常是张量并行大小和管道并行大小的乘积。如果可能,会自动使用多个实例。
3. 测试每个配置并测量性能
对于每个定义的配置:
3.1. 部署配置
使用 MLNode REST API 端点部署当前配置:
http://<IP>:<MANAGEMENT_PORT>/api/v1/inference/up
import requests
from typing import List, Optional
def inference_up(
base_url: str,
model: str,
config: dict
) -> dict:
url = f"{base_url}/api/v1/inference/up"
payload = {
"model": model,
"dtype": "float16",
"additional_args": config["args"]
}
response = requests.post(url, json=payload)
response.raise_for_status()
return response.json()
model_name = "MODEL_NAME"
model_config = {
"args": [
"--quantization", "fp8",
"--tensor-parallel-size", "8",
"--pipeline-parallel-size", "1",
"--kv-cache-dtype", "fp8"
]
}
inference_up(
base_url="http://<IP>:<MANAGEMENT_PORT>",
model=model_name,
config=model_config
)
3.2. 验证部署
- 检查 MLNode 日志中是否有部署过程中可能发生的任何错误。
- 通过检查 REST API 端点
http://<IP>:<MANAGEMENT_PORT>/api/v1/state验证部署状态。
预期状态:
{'state': 'INFERENCE'}
3.3. 测量性能
运行 compressa-perf 工具来测量已部署配置的性能并收集相关指标。
4. 比较各配置的性能结果
分析从每个测试配置收集的指标(如 TTFT、延迟 和 吞吐量)。比较这些结果以确定在服务器环境中提供最佳性能的设置。
示例:8x4070 STi 服务器上的 Qwen/QwQ-32B
假设我们有一台配备 8x4070 S Ti 的服务器。每个 GPU 有 16GB VRAM。
我们已将 MLNode 容器部署到此服务器,具有以下端口映射:
- API 管理端口(默认 8080)映射到
http://24.124.32.70:46195 - 推理端口(默认 5000)映射到
http://24.124.32.70:46085
对于此示例,我们将使用 Qwen/QwQ-32B 模型,这是在 Gonka 部署的模型之一。它具有以下强制参数:
--kv-cache-dtype fp8--quantization fp8
1. 使用强制参数建立初始配置
基于这些强制参数,Qwen/QwQ-32B 的初始配置必须包括:
"Qwen/QwQ-32B": {
"args": [
"--kv-cache-dtype", "fp8",
"--quantization", "fp8",
...
]
}
2. 定义用于测试的潜在部署配置
具有这些参数的 Qwen/QwQ-32B 模型需要至少 80GB 的 VRAM 才能有效部署。因此,我们需要为每个实例使用至少 6x4070S Ti。我们无法在此服务器中容纳两个实例并希望使用所有 GPU,让我们部署一个使用 8 个 GPU 的单个实例(TP * PP = 8)。
潜在配置可以包括:
- TP=8, PP=1
- TP=4, PP=2
- TP=2, PP=4
- TP=1, PP=8
高管道并行性通常在单服务器部署中不会产生良好的性能。因此,在此示例中,我们只测试两种配置:
- 配置 1(TP=8,PP=1)。
- 配置 2(TP=4,PP=2)
3. 部署和测量每个配置
3.1 配置 1(TP=8,PP=1)
3.1.1. 部署
使用 Python 脚本部署模型:
...
model_name = "Qwen/QwQ-32B"
model_config = {
"args": [
"--quantization", "fp8",
"--tensor-parallel-size", "8",
"--pipeline-parallel-size", "1",
"--kv-cache-dtype", "fp8"
]
}
inference_up(
base_url="http://24.124.32.70:46195",
model=model_name,
config=model_config
)
{"status": "OK"}
3.1.2. 验证部署
在 MLNode 日志中,我们看到 vLLM 已成功部署:
...
INFO 05-15 23:50:01 [api_server.py:1024] Starting vLLM API server on http://0.0.0.0:5000
INFO 05-15 23:50:01 [launcher.py:26] Available routes are:
INFO 05-15 23:50:01 [launcher.py:34] Route: /openapi.JSON, Methods: GET, HEAD
INFO 05-15 23:50:01 [launcher.py:34] Route: /docs, Methods: GET, HEAD
INFO 05-15 23:50:01 [launcher.py:34] Route: /docs/oauth2-redirect, Methods: GET, HEAD
INFO 05-15 23:50:01 [launcher.py:34] Route: /redoc, Methods: GET, HEAD
INFO 05-15 23:50:01 [launcher.py:34] Route: /health, Methods: GET
INFO 05-15 23:50:01 [launcher.py:34] Route: /load, Methods: GET
INFO 05-15 23:50:01 [launcher.py:34] Route: /ping, Methods: GET, POST
INFO 05-15 23:50:01 [launcher.py:34] Route: /tokenize, Methods: POST
INFO 05-15 23:50:01 [launcher.py:34] Route: /detokenize, Methods: POST
INFO 05-15 23:50:01 [launcher.py:34] Route: /v1/models, Methods: GET
INFO 05-15 23:50:01 [launcher.py:34] Route: /version, Methods: GET
INFO 05-15 23:50:01 [launcher.py:34] Route: /v1/chat/completions, Methods: POST
INFO 05-15 23:50:01 [launcher.py:34] Route: /v1/completions, Methods: POST
INFO 05-15 23:50:01 [launcher.py:34] Route: /v1/embeddings, Methods: POST
INFO 05-15 23:50:01 [launcher.py:34] Route: /pooling, Methods: POST
INFO 05-15 23:50:01 [launcher.py:34] Route: /score, Methods: POST
INFO 05-15 23:50:01 [launcher.py:34] Route: /v1/score, Methods: POST
INFO 05-15 23:50:01 [launcher.py:34] Route: /v1/audio/transcriptions, Methods: POST
INFO 05-15 23:50:01 [launcher.py:34] Route: /rerank, Methods: POST
INFO 05-15 23:50:01 [launcher.py:34] Route: /v1/rerank, Methods: POST
INFO 05-15 23:50:01 [launcher.py:34] Route: /v2/rerank, Methods: POST
INFO 05-15 23:50:01 [launcher.py:34] Route: /invocations, Methods: POST
INFO: Started server process [4437]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: 127.0.0.1:37542 - "GET /v1/models HTTP/1.1" 200 OK
requests.get(
"http://24.124.32.70:46195/api/v1/state"
).JSON()
{'state': 'INFERENCE'}
3.1.3. 测量性能
开始性能测试:
compressa-perf \
measure-from-yaml \
--no-sign \
--node_url http://24.124.32.70:46085 \
--model_name Qwen/QwQ-32B \
config.yml
如果发生错误请检查日志
配置可能仍然无法按预期工作;如果发生错误,请检查 MLNode 日志进行故障排除。
测试完成后,我们可以看到结果:
compressa-perf list --show-metrics --show-parameters
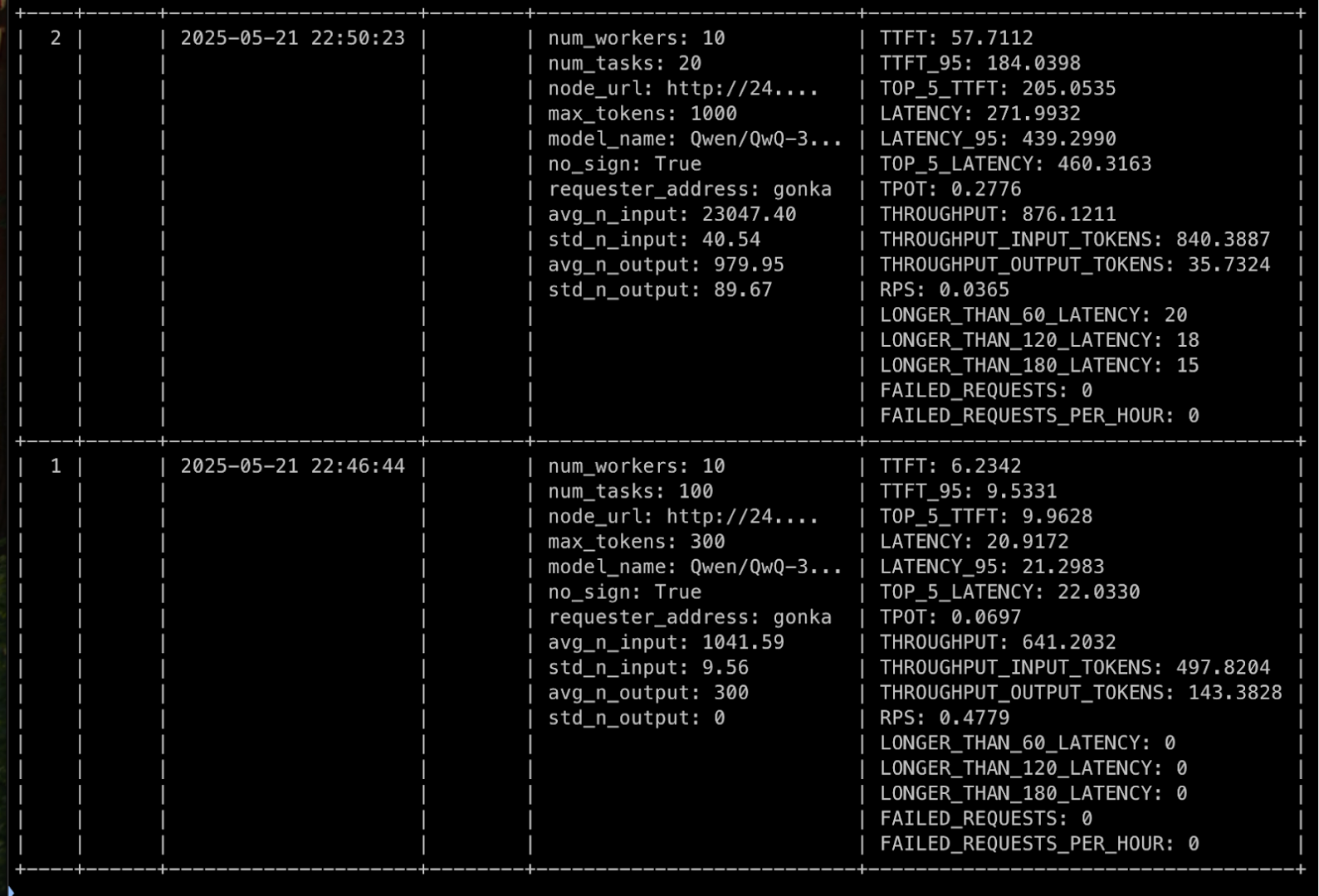
3.2. 配置 2(TP=4,PP=2)
3.2.1. 部署
使用 Python 脚本部署模型:
...
model_name = "Qwen/QwQ-32B"
model_config = {
"args": [
"--quantization", "fp8",
"--tensor-parallel-size", "4",
"--pipeline-parallel-size", "2",
"--kv-cache-dtype", "fp8"
]
}
inference_up(
base_url="http://24.124.32.70:46195",
model=model_name,
config=model_config
)
{"status": "OK"}
3.2.2. 验证部署
检查日志显示成功部署,/api/v1/state 仍然返回 {'state': 'INFERENCE'}
3.2.3. 测量性能
使用相同命令第二次测量性能:
compressa-perf \
measure-from-yaml \
--no-sign \
--node_url http://24.124.32.70:46085 \
--model_name Qwen/QwQ-32B \
config.yml
compressa-perf list --show-metrics --show-parameters
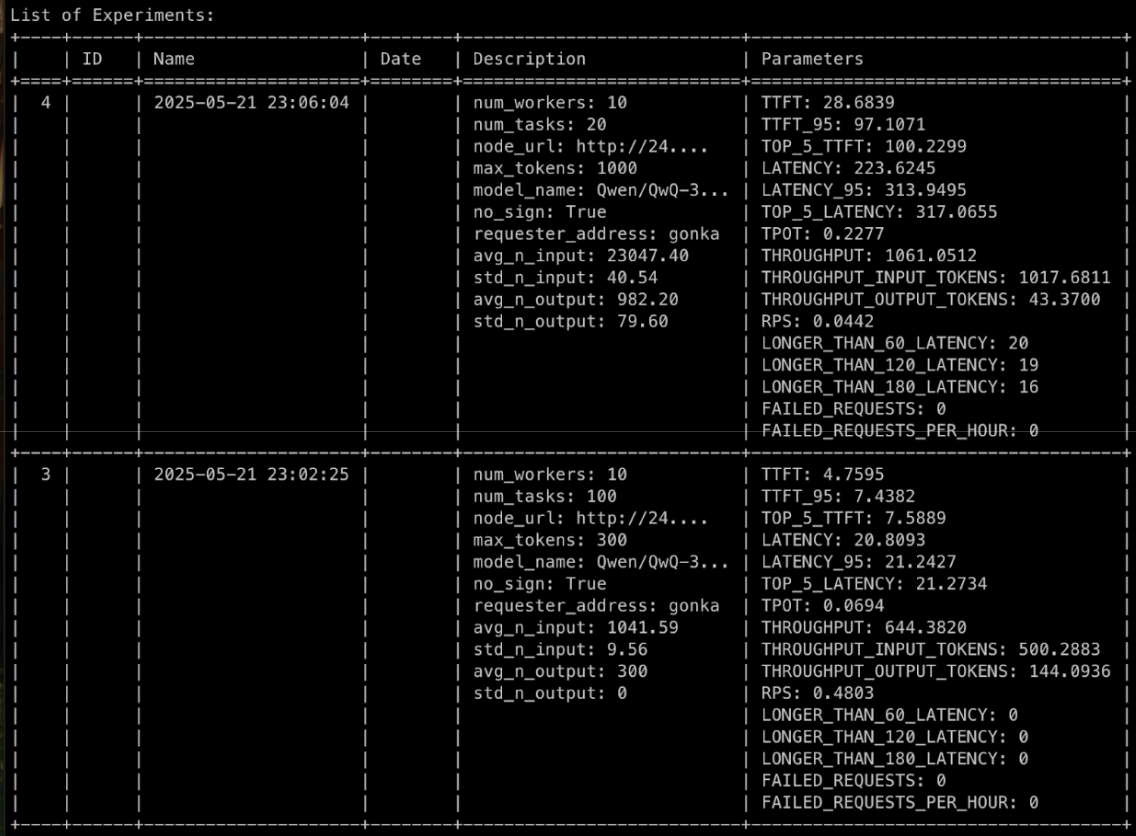
4. 比较各配置的性能结果
我们的实验显示以下指标:
| 实验 | 指标 | TP 8, PP 1 | TP 4, PP 2 |
|---|---|---|---|
| ~1000 令牌输入 / ~300 令牌输出 | TTFT | 6.2342 | 4.7595 |
| ~1000 令牌输入 / ~300 令牌输出 | 输入吞吐量 | 497.8204 | 500.2883 |
| ~1000 令牌输入 / ~300 令牌输出 | 输出吞吐量 | 143.3828 | 144.0936 |
| ~1000 令牌输入 / ~300 令牌输出 | 延迟 | 20.9172 | 20.8093 |
| ~23000 令牌输入 / ~1000 令牌输出 | TTFT | 57.7112 | 28.6839 |
| ~23000 令牌输入 / ~1000 令牌输出 | 输入吞吐量 | 840.3887 | 1017.6811 |
| ~23000 令牌输入 / ~1000 令牌输出 | 输出吞吐量 | 35.7324 | 43.3700 |
| ~23000 令牌输入 / ~1000 令牌输出 | 延迟 | 271.9932 | 223.6245 |
TP=4 和 PP=2 设置显示了一致的更好性能,我们应该使用它。